
Engineering Incident Communication Playbook should be treated as a repeatable operating system, not a one-off project. Start narrow, instrument outcomes, and optimize each cycle with clear ownership.
Key Takeaways
- Define one user moment, one trigger, and one measurable outcome.
- Track leading KPI movement before scaling breadth.
- Use next-step internal links to keep execution momentum.
1. Scope one high-impact workflow
Most implementation delays come from over-scoping. Start with one target segment and one action path so your first signal is clean and comparable.
2. Design the end-to-end workflow
Map input, decision logic, quality checks, and execution logging. Add fallback and escalation rules from day one.
- Input capture and context normalization
- Model or rules decision stage
- Quality review and override path
- Execution logging and weekly review
3. Instrument KPI checkpoints
Track retention rate, cost per outcome, and downstream business outcomes. Avoid vanity metrics until quality and reliability are stable.
5-Minute Launch Checklist
- Baseline metric captured pre-launch.
- Owner assigned for weekly KPI review.
- Fallback behavior documented and tested.
- One next experiment queued for sprint two.
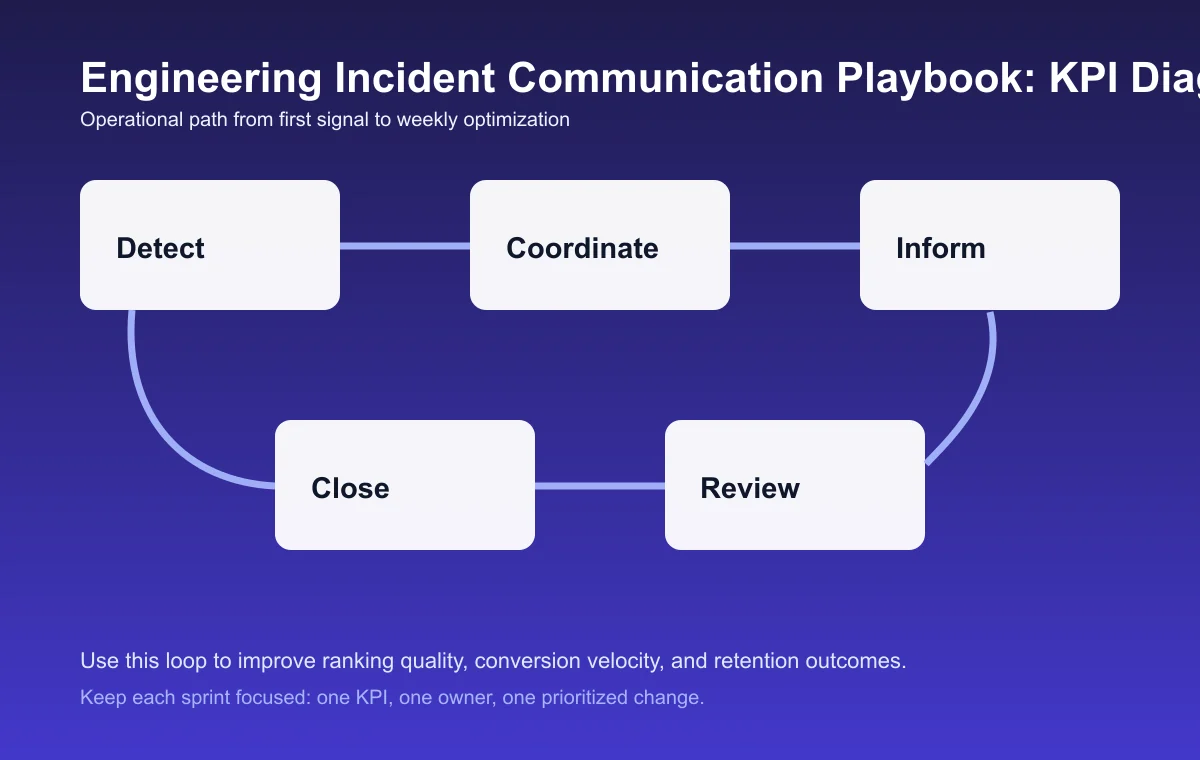
4. Run a weekly execution loop
- Prioritize one high-impact change tied to one KPI.
- Ship with QA gates and fallback behavior.
- Review outcomes and failure patterns.
- Decide what to scale, revise, or stop.
5. Avoid common implementation mistakes
- Expanding scope before stable metric movement
- No owner for weekly optimization decisions
- No fallback behavior for edge cases
- Prioritizing traffic over value metrics
Final takeaway
Engineering Incident Communication Playbook drives durable results when teams keep scope focused, measure outcomes weekly, and follow an explicit optimization rhythm.
Continue with Release Readiness Checklist Framework, Go-To-Market Messaging Framework, and Security Awareness Training System.
Choose Your Next Step
Use these stage-based reads to keep momentum and avoid jumping between unrelated tasks.
Frequently Asked Questions
What should we launch first in Engineering Incident Communication Playbook?
Start with one high-impact workflow, one owner, and one KPI baseline. Then iterate weekly before expanding scope.
Which metrics matter most early?
Track retention rate and cost per outcome first. They reveal if the system creates real operational value.
How do we scale without quality drops?
Use fallback rules, quality reviews, and a fixed weekly optimization cycle with ownership and clear thresholds.